-
Apache Kafka카테고리 없음 2024. 6. 17. 11:34
https://www.youtube.com/watch?v=Ch5VhJzaoaI
Kafka: 실시간으로 기록 스트림을 게시, 구독, 저장 및 처리할 수 있는 분산형 데이터 스트리밍 플랫폼
1. Producer가 많은 데이터를 생성함에 따라 Queue 하나로는 Computing Power가 부족해지는 현상이 발생

2. Queue를 늘리고 Contents를 Distribute 해서 병목현상을 해결
3. Distribute 방식은 아래 그림처럼 특정 분류기준을 가지고 나누어서 분류하게 됨

4. 용어
1) Partition - Queue 한개씩
2) Broker - Partition이 있는 서버
3) Record - Queue 안에 있는 아이템
4) Partition Key - 파티션을 나누는 데 사용하는 키. 지정되지 않으면 Random Partition
5) Topic - 같은 타입의 데이터를 다루는 파티션의 집합
6) Offset - Partition내 Record에 주어지는 Sequential Number
- Record의 위치는 Partition Number, Offset으로 표현됨

5. Consumer도 여러개로 Parallelize 할수있음

6. 이 Parallelized Consumer Group은 같은 Partition Record를 읽지 않고. 각각 다른 Partition을 읽게 됨
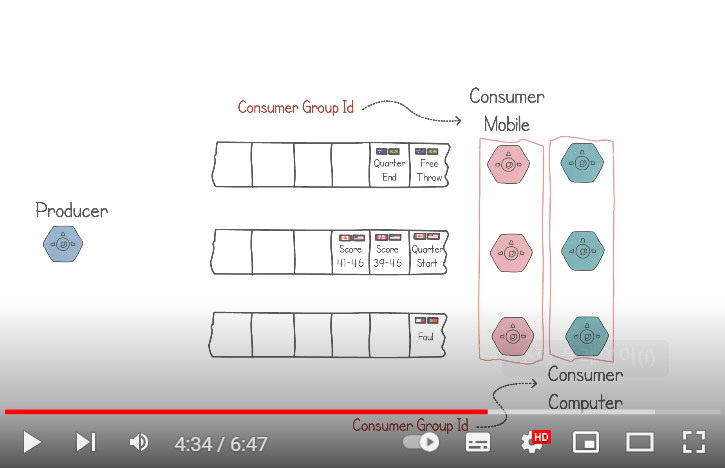
7. Mobile Consumer Group과 Computer Consumer Group이 서로 다른 포인터를 갖게 됨.
마지막 Record만 갖고있으면 되었는데 Consumer Group이 다 다른 곳을 읽고 있으니
그럼 Kafka는 Record Cleanup을 어떻게 하지? 에 대한 답변이 3가지가 있음

8. Record Clean up 방식
1) Age limit - 24시간 지나면 삭제

2) Fault Tolerance & Durable - Persistent Storage에 Record를 모두 저장해서 Broker가 죽어도 Backup 가능하게

3) Replication Factor - Broker가 죽더라도 Backup을 구비해 두는 것
Replication Factor = 3이면 1개의 Leader, 2개의 Backup이 있는 것

처리할 때 Scailability, Redundancy 측면에서 좋은 솔루션이다.
* Redundancy : 정상 동작에 필요한 정도 이상의 여분의 장치/기능을 부가하여 안정성을 높임